

Before diving into the specifics, let’s look at why developers should consider Big O Notation when writing algorithms. Big-O tells you the complexity of an algorithm in terms of the size of its inputs. This is essential if you want to know how algorithms will scale.
If you need to design a big website and expect a lot of users, the time it takes you to handle user requests is critical. If the expectations are to store a large amount of data in a structure then you will need to know how to do that efficiently otherwise you could end up writing something that takes a million years to process, creating a terrible user experience (UX). Ultimately, Big-O notation helps you determine which algorithms are fast, which are slow, and the tradeoffs.
What Exactly is Big “O” Notation?
After reading a few articles, here is my takeaway….
Software is heavily based on data; vast mountains of data and our job is to make use of that data. For a program to utilize this data, it must be able to sort the information. It would help if this sorting were done in a logical order, whether that is alphabetically, chronologically, or by date. This type of sorting is done constantly and represents a large portion of all computer and internet activity.
Sorting data is a subsection within the computer science community. There are many different algorithms used for sorting. The quick sort, bubble sort, selection sort, merge sort, heap sort and many others. Each has a different approach, but the results tend to be the same or similar.
Which Method is Best or Most Efficient?
If I needed my car fixed and knew of 3 mechanics who could get the job done, all within a reasonable price range and offer good service, my next question would be how long is it going to take? Insert Big O Notation. Yes, all these sorting methods get the job done but which method is quickest for what you’re trying to accomplish?
Big O notation analyzes how many operations a sorting algorithm needs to complete in order to sort a very large collection of data. This process measures the efficiency of the sort and lets the user compare one algorithm to another. For smaller applications this might not move the needle very much but when working with large amounts of data, minor differences between algorithms can make a huge difference!
“Big O notation ranks an algorithms’ efficiency.
It does this with regard to “O” and “n”, (example: “O(log n)” ), where
- O refers to the order of the function, or its growth rate, and
- n is the length of the array to be sorted.
Let us work through an example. If an algorithm has the number of operations required formula of:
f(n) = 6n⁴ — 2n³ + 5
As “n” approaches infinity (for very large sets of data), of the three terms present, 6n⁴ is the only one that matters. So, the lesser terms, 2n³ and 5, are actually just omitted because they are insignificant. Same goes for the “6” in 6n⁴.
Therefore, this function would have an order growth rate, or a “big O” rating, of O(n⁴) .
When looking at many of the most commonly used sorting algorithms, the rating of O(n log n) in general is the best that can be achieved. Algorithms that run at this rating include Quick Sort, Heap Sort, and Merge Sort. Quick Sort is the standard and is used as the default in almost all software languages.”
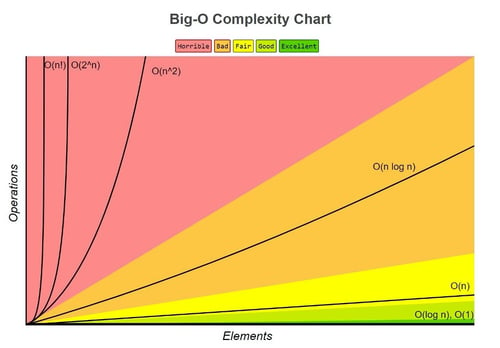
In looking at this chart it is helpful to remember that there is no single algorithm or calculation that rules them all. Each procedure will have a best- and worst-case scenario where they perform at their best and worst.
After looking further into the sorting algorithms, it seemed to me that Quick Sort is the standard.
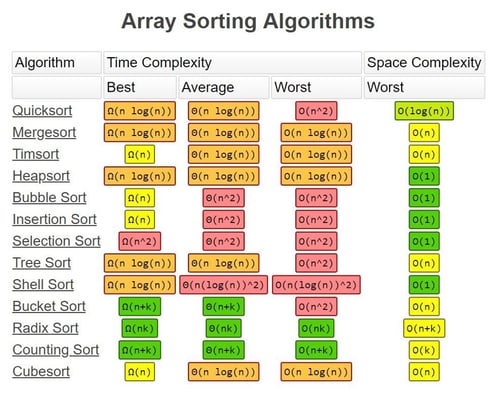
- Quick sort =Works best on large lists that are completely scrambled. It has really bad performance on lists that are almost sorted. The most direct competitor of Quick sort is Heap sort.
- Heap Sort = Finds the largest element in an unsorted collection and orders it at the back of the list. Running time is O(n log n), negative is that the average running time is usually slower than in-place Quick Sort
- Merge Sort =Stable sort, preserves the input order of equal elements in the output, something that Quick and Heap sort fail to do. Useful for sorting linked lists.
- Bubble/Insertion/Selection sort= Running time of O(n²), takes significantly longer than those with a run time of O(n log n) when dealing with very large amounts of data.









Comments
Add Comment